고가용성 기능의 필요성
- 복제 구성으로만 레디스를 사용하고 있었다면 마스터 노드에 발생한 장애 처리가 지연돼 곧바로 서비스 기능의 문제로 이어질 수 있다.
- look aside 구성에서는 애플리케이션이 캐시에 접근할 수 없을 때 캐시 스탬피드 현상이 일어나 서비스에 영향을 끼칠 수 있다.
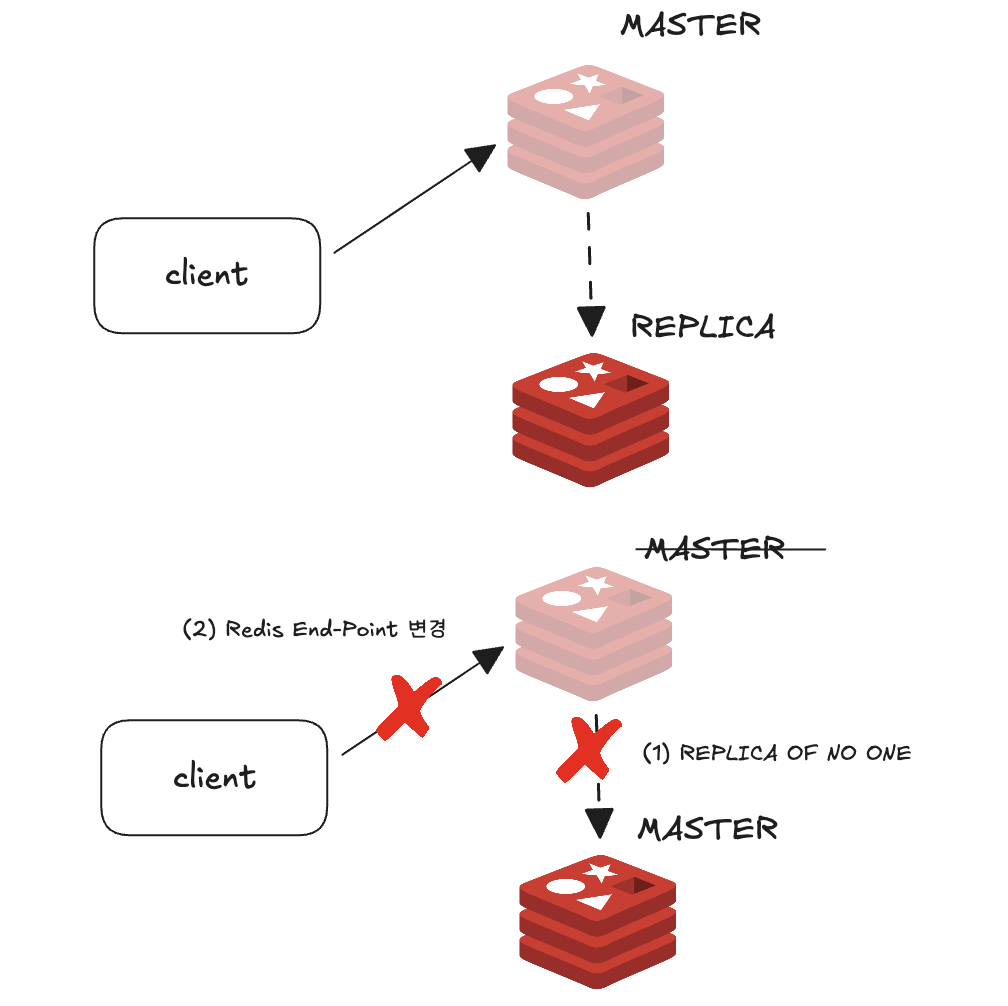
1. 복제본 노드에 직접 접속한 뒤 REPLICA OF NO ONE 커맨드를 입력해 읽기 전용 상태 해제
2. 애플리케이션 코드에서 레디스의 엔드포인트를 복제본의 IP로 변경
3. 배포
센티널이란?
- 센티널: 레디스의 자체 고가용성 기능
- 센티널의 자동 페일오버 기능을 사용하면 마스터 인스턴스에 장애가 발생하더라도 레디스를 계속 사용할 수 있도록 동작해 레디스의 다운타임을 최소화할 수 있다.
센티널 기능
- 모니터링
- 자동 페일오버 - 마스터의 비정상 상태를 감지해 정상 상태의 복제본 중 하나를 마스터로 승격시킴
- 인스턴스 구성 정보 안내

분산 시스템으로 동작하는 센티널
- 센티널은 SPOF가 되는 것을 방지하기 위해 최소 3대 이상일 때 정상적으로 동작할 수 있도록 설계되었다.
- 쿼럼이라는 개념을 사용한다.
- 쿼럼: 마스터가 비정상 동작을 한다는 것에 동의해야 하는 센티널의 수
- 일반적으로 센티널 인스턴스가 3개일 때 쿼럼은 2로 설정한다.
- 과반수 선출 개념을 사용하기 때문에 3대 이상의 홀수로 구성하는 것이 좋다.
센티널 인스턴스 배치 방법
서로 다른 가용 영역에 배치하는 것이 일반적이다.
2개의 복제본이 있는 구성
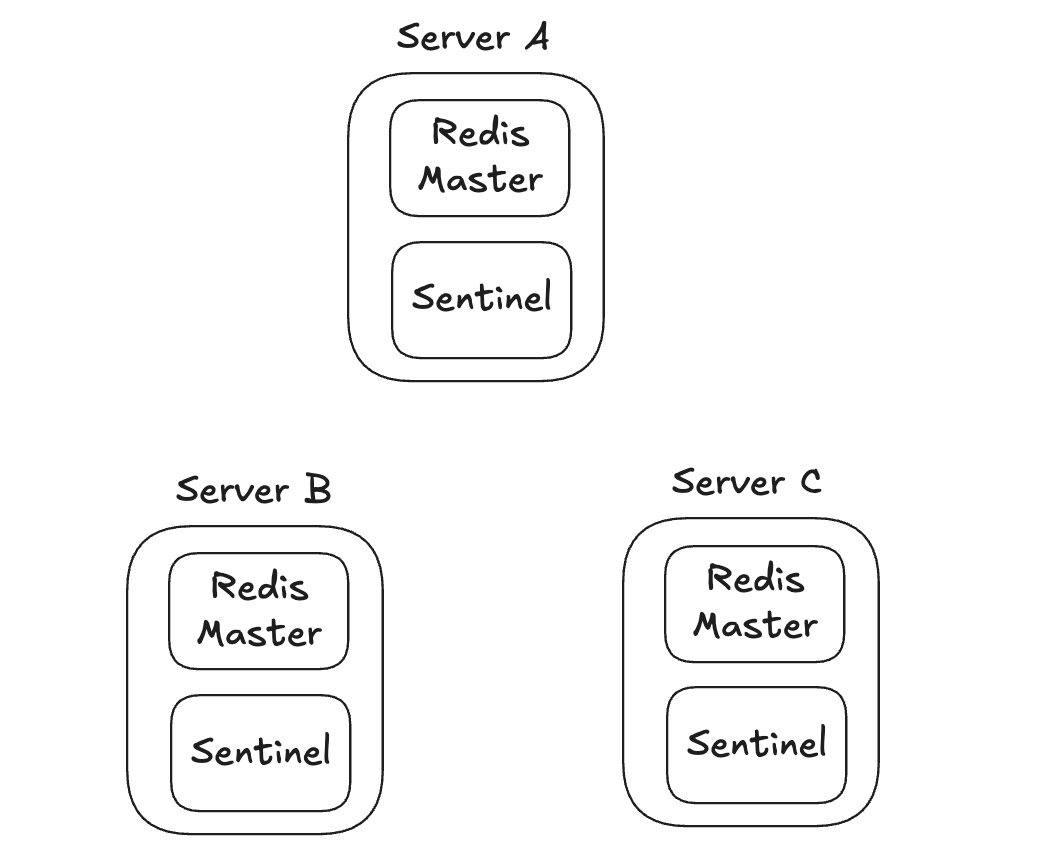
- 보통 하나의 서버에 레디스 프로세스와 센티널 프로세스를 동시에 실행시킨다.

- 새롭게 마스터가 될 복제본을 선출한 뒤, 해당 복제본 인스턴스를 마스터로 승격시킨다.
- 기존 마스터를 바라보고 있던 클라이언트는 모두 서버 B에서 새롭게 선출된 마스터로 연결된다.
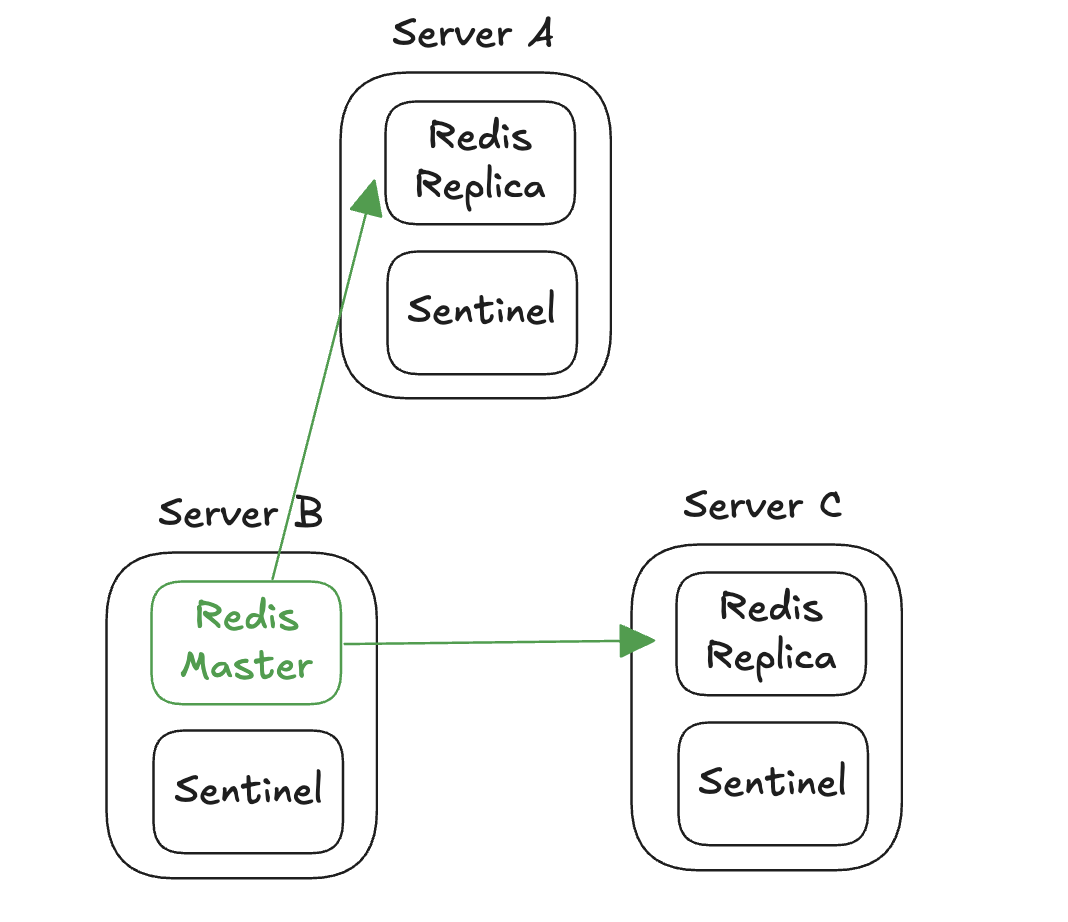
- 서버 A가 복구되면 센티널 인스턴스의 판단으로 자동으로 구성된다.
- 서버 리소스에 여유가 있다면 2개의 복제본을 가질 수 있도록 구성하는 것이 안정적이다.
1개의 복제본이 있는 구성
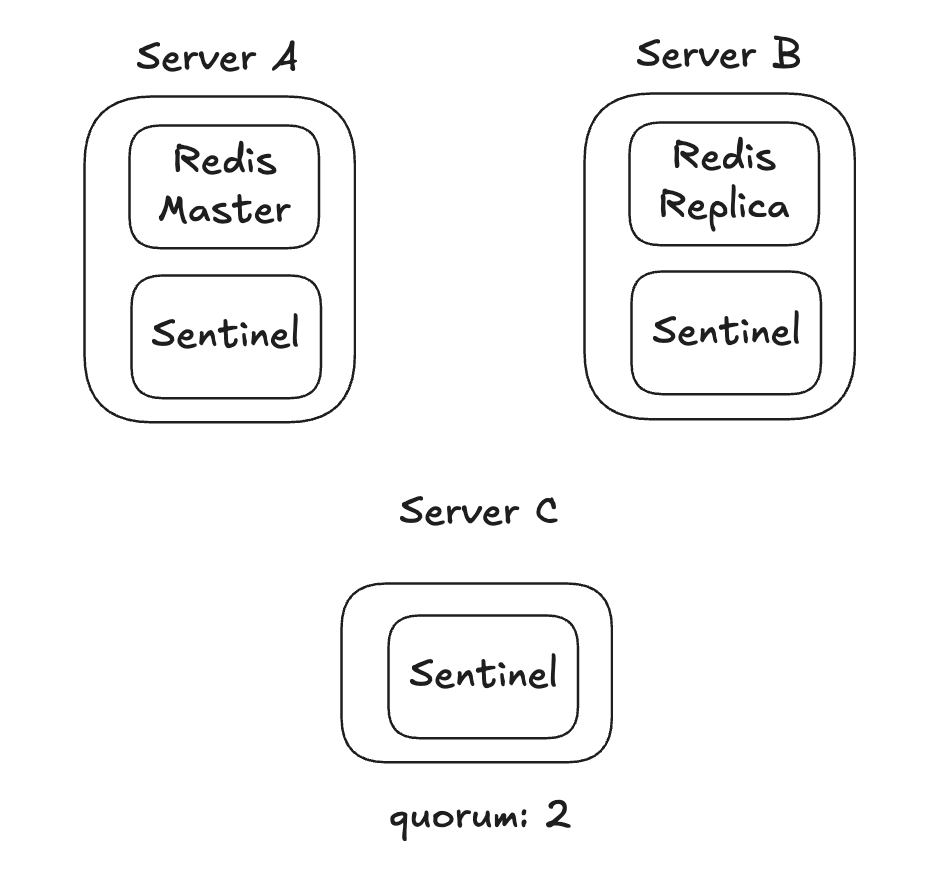
- 나머지 1대의 서버에는 센티널 프로세스만 실행시킬 수 있다.
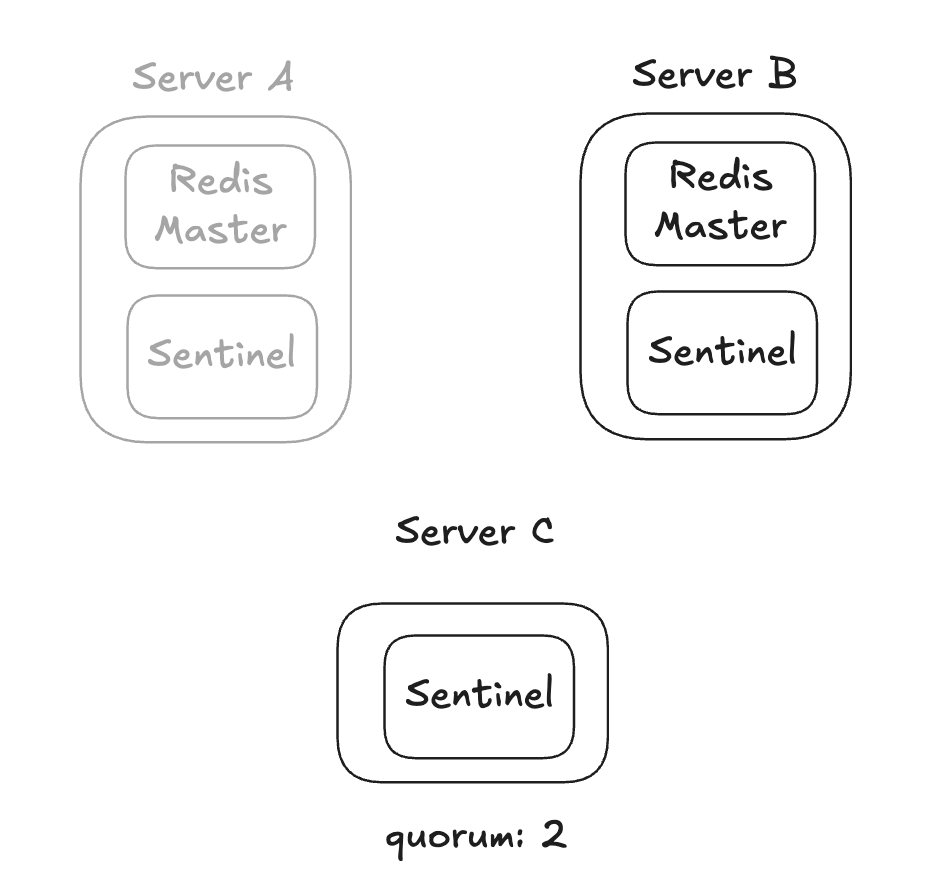
- 서버 A에 문제가 생기면 페일오버를 진행시킨다.
- 서버 C를 최저 사양으로 구성해 리소스 비용을 아끼면서도 마스터의 장애를 감지해 자동 페일오버를 수행할 수 있는 안정적인 구조다.
센티널 인스턴스 실행하기
2대의 서버에는 레디스와 센티널을 모두 띄우고, 1대 서버에는 센티널 프로세스만 띄운 구성 기준으로 진행된다.
- 레디스 프로세스: 6379 포트
- 센티널 프로세스: 26379 포트
센티널 프로세스 실행
REPLICAOF <master-host> 6379복제본 노드에서 복제 연결을 시작한다.
port 26379
sentinel monitor master-test 6379 2센티널 프로세스를 띄우기 위해 sentinel.conf라는 별도의 구성 파일이 필요하다.
- port: 센티널 프로세스가 실행될 포트
- sentinel monitor: 모니터링할 마스터의 이름 지정, 마스터에 이름 부여, 쿼럼 값 지정
- 구성 파일에는 복제본 정보를 직접 입력하지 않아도 된다.
# redis-sentinel을 이용하는 방법
redis-sentinel /path/to/sentinel.conf
# redis-server를 이용하는 방법
redis-server /path/to/sentinel.conf --sentinel2가지 방법 중 하나로 센티널을 실행시킨다.
$ redis-cli -p 26379센티널 인스턴스에 직접 접근할 수 있다.
sentinel> SENTINEL master <master-name>마스터의 다양한 정보를 확인할 수 있다.
- num-other-sentinels 플래그: 마스터를 모니터링하고 있는 다른 센티널의 정보를 나타낸다.
- flags 플래그: 마스터의 상태를 나타낸다.
- num-slaves 플래그: 현재 마스터에 연결된 복제본의 개수를 나타낸다.
sentinel> SENTINEL replicas master-test(레디스) 마스터에 연결된 복제본의 자세한 정보를 확인할 수 있다.
sentinel> SENTINEL sentinels master-test(센티넬) 마스터에 연결된 복제본의 자세한 정보를 확인할 수 있다.
sentinel> SENTINEL ckquorum master-test마스터를 바라보고 있는 센티널 인스턴스가 설정한 쿼럼 값보다 큰지 확인할 수 있다. (작으면 error)
페일오버 테스트
커맨드를 이용한 페일오버 발생(수동 페일오버)
SENTINEL FAILOVER <master name>다른 센티널의 동의를 구하지 않고 페일오버를 바로 발생시킨다.
마스터 동작을 중지시켜 페일오버 발생(자동 페일오버)
$ redis-cli -h <master-host> -p <master-port> shutdown직접 마스터 노드에 장애를 발생시켜 페일오버가 잘 발생하는지 확인한다. (레디스의 프로세스를 직접 셧다운)
센티널 운영하기
패스워드 인증
- 마스터와 복제본 노드에 패스워드를 설정한 경우 센티널의 설정 파일에서도 패스워드를 지정해야 한다.
- 하나의 복제 그룹에서 requirepass와 masterauth 값은 모든 노드에서 동일하게 설정해야 한다.
sentinel auth-pass <master-name> <password>패스워드가 걸려 있는 레디스를 모니터링할 경우에는 sentinel.conf에 패스워드를 지정해야 한다.
복제본 우선순위
- 센티널은 페일오버를 진행할 때 각 복제본 노드의 replica-priority라는 우선순위 노드를 확인하며, 해당 값이 가장 작은 노드를 마스터로 선출한다.
- 기본값: 100
- 0인 복제본은 마스터로 선출되지 않음
운영 중 센티널 구성 정보 변경
SENTINEL MONITOR <master name> <ip> <port> <quorum>
센티널이 새로운 마스터를 모니터링할 수 있도록 한다.
SENTINEL REMOVE <master name>더 이상 지정하는 마스터를 모니터링하지 않도록 지시한다.
SENTINEL SET <name> [<option> <value> ...]특정 마스터에 대해 지정한 파라미터를 변경할 수 있다.
- down-after-milliseconds: 마스터가 다운됐다는 것을 판단하는 시간
- quorum: 쿼럼 값
센티널 초기화
서버를 더 이상 사용할 수 없어 해당 인스턴스에 대한 모니터링을 중단하려면 SENTINEL REST 커맨드를 사용해 센티널 인스턴스의 상태 정보를 초기화해야 한다.
SENTINEL RESET <master name>센티널 인스턴스의 상태 정보를 초기화하고 센티널이 모니터링하고 있는 마스터, 복제본, 다른 센티널 인스턴스의 정보를 새로 고친다.
센티널 노드의 추가/제거
- 추가: 마스터를 모니터링하도록 설정한 센티널 인스턴스를 실행시킨다.
- 제거: SENTINEL RESET * 커맨드를 이용해 센티널이 모니터링하고 있는 정보를 리셋한다.
센티널의 자동 페일오버 과정
마스터의 장애 상황 감지
지정된 값 이상 동안 마스터에 보낸 PING에 대해 유효한 응답을 받지 못하면 마스터가 다운됐다고 판단한다.
- 유효한 응답: +PONG, -LOADING, -MASTERDOWN
- 그 외 응답 또는 받지 못했을 경우 유효하지 않음으로 판단
sdown, odown 실패 상태로 전환
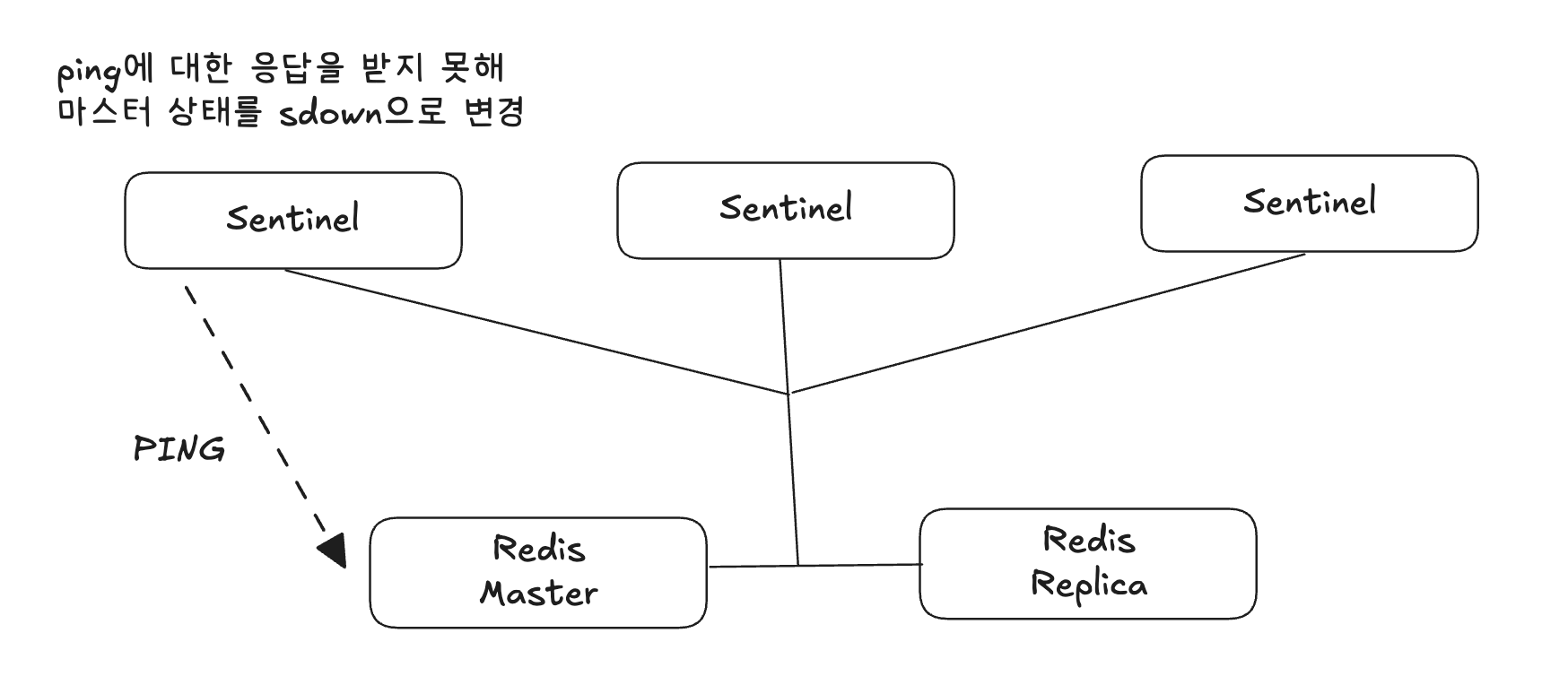
- 하나의 센티널 노드에서 마스터 인스턴스에 대한 응답을 늦게 받으면 마스터 상태를 우선 sdown으로 플래깅한다.
- sdown: subjectly down, 주관적인 다운 상태
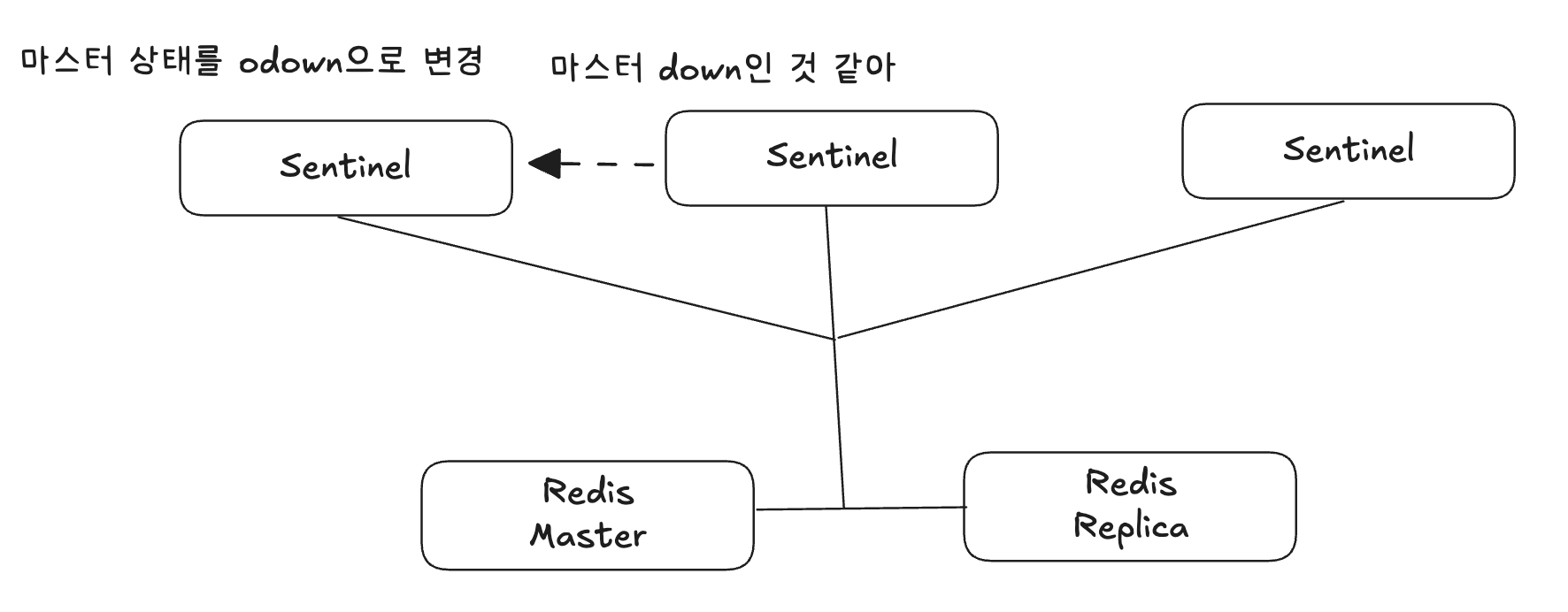
- 이후 다른 센티널 노드들에게 SENTINEL is-master-down-by-addr <master-ip> <master-port> <current-epoch> <*>라는 커맨드를 보내 다른 센티널에게 장애 사실을 전파한다.
- 쿼럼 값 이상의 센티널 노드에서 마스터의 장애를 인지한다면 센티널 노드는 마스터의 상태를 odown으로 변경한다.
- odown: objectly down, 객관적인 다운 상태
에포크 증가
처음으로 마스터 노드를 odown으로 인지한 센티널 노드가 페일오버 과정을 시작한다.
- 페일오버 시작 전 에포크(epoch) 값을 하나 증가시킨다.
- 새로운 페일오버가 발생할 때마다 에포크 값은 하나씩 증가한다.
- 동일한 에포크 값을 이용해 페일오버 과정이 진행되는 동안 모든 센티널 노드가 같은 작업을 시도하고 있다는 것을 보장한다.
센티널 리더 선출

에포크를 증가시킨 센티널은 리더를 선출하기 위해 투표하라는 메시지를 보낸다.
복제본 선정 후 마스터로 승격
과반수 이상의 센티널이 페일오버에 동의했다면 리더 센티널은 페일오버를 시도하기 위해 마스터가 될 수 있는 적당한 복제본을 선정한다.
- redis.conf 파일에 명시된 replica-priority가 낮은 복제본
- 마스터로부터 더 많은 데이터를 수신한 복제본
- 2번 조건까지 동일하다면, runID가 사전 순으로 작은 복제본
선정한 복제본에는 slaveof no one 커맨드를 수행해, 기존 마스터로부터 복제를 끊는다.
복제 연결 변경
복제본마다 replicaof new-ip new-port 커맨드를 수행해 복제 연결을 변경한다.
장애 조치 완료
모든 과정 완료 후 센티널은 새로운 마스터를 모니터링한다.
스플릿 브레인 현상
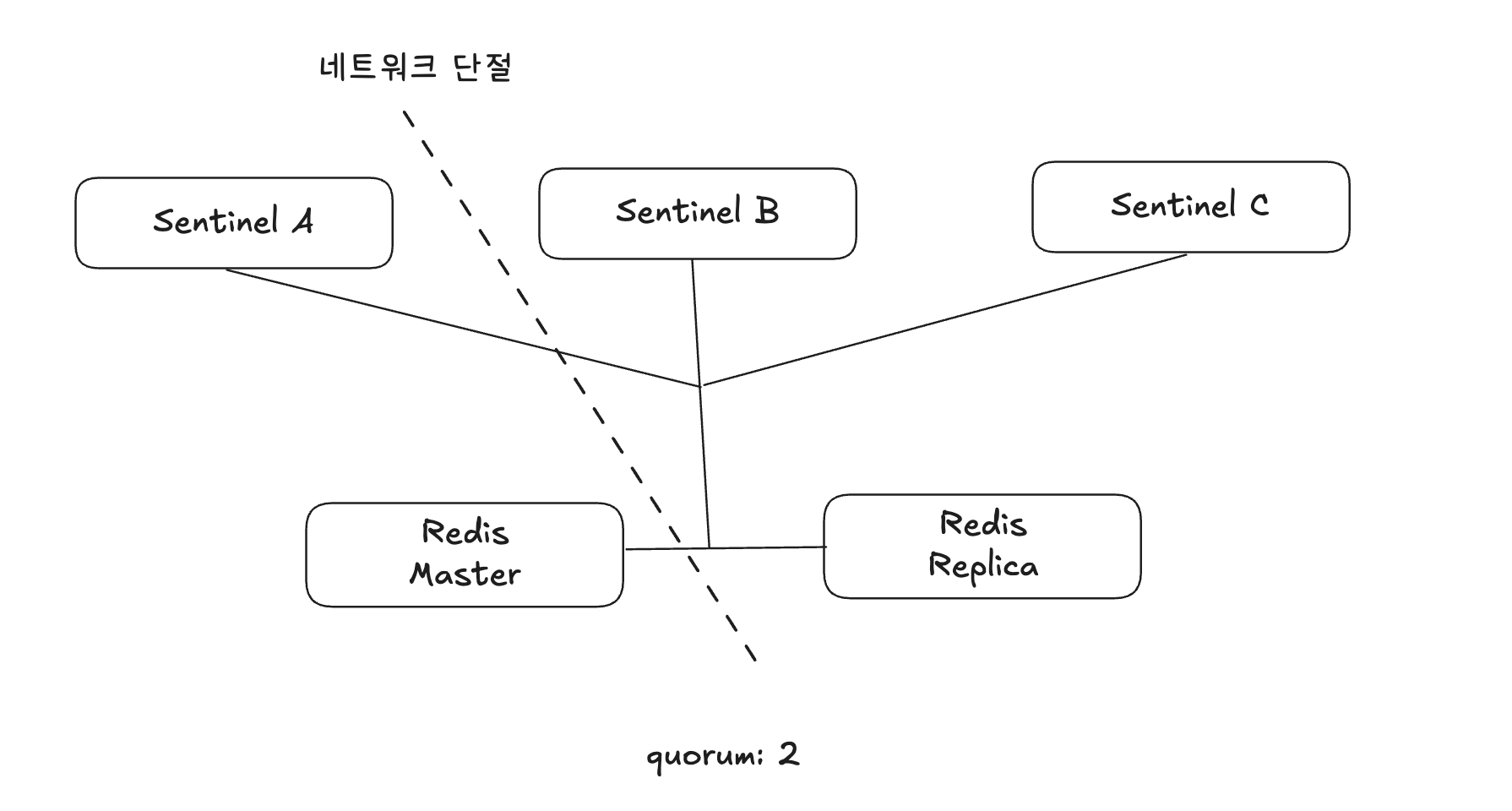
스플릿 브레인 현상: 네트워크 파티션 이슈로 인해 분산 환경의 데이터 저장소가 끊어지고, 끊긴 두 부분이 각각을 정상적인 서비스라고 인식하는 현상
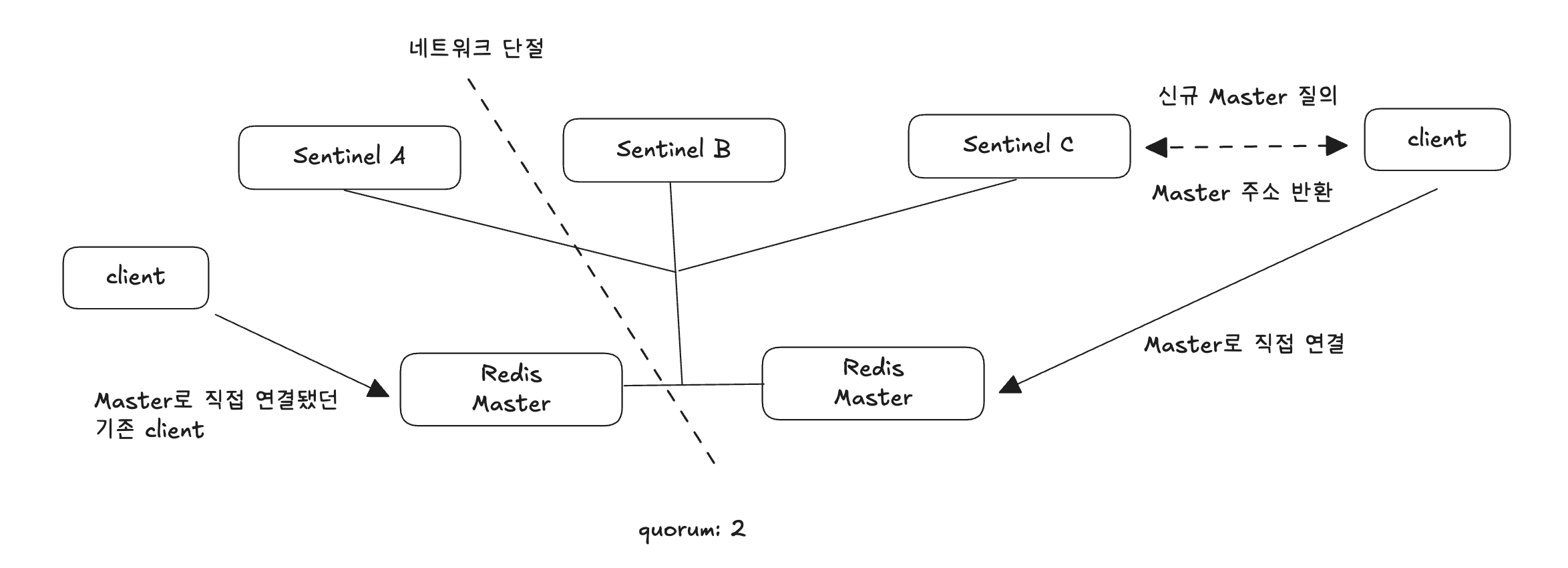
하나의 복제본에 2개의 마스터가 생기는 스플릿 브레인 현상이 일어난다.
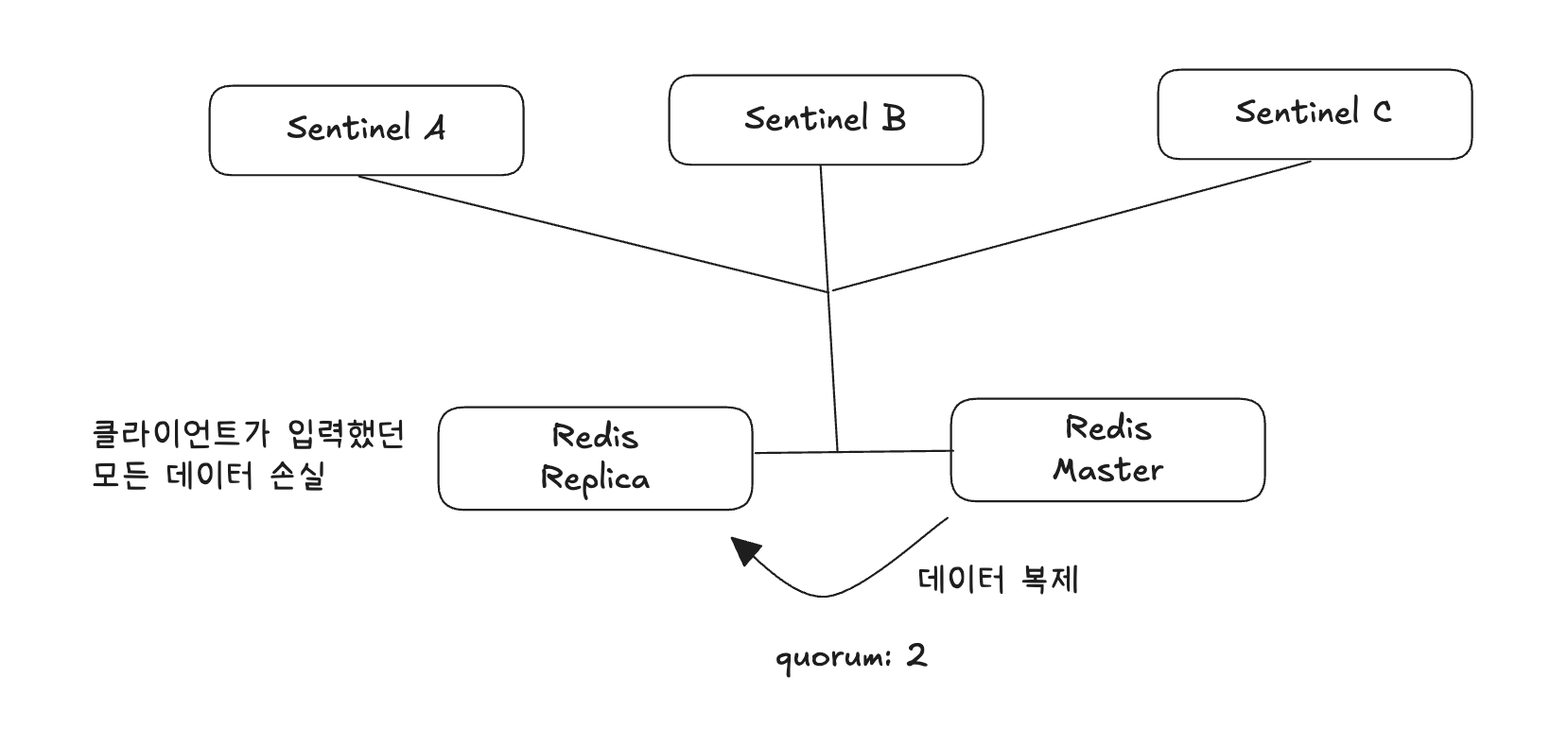
복제본으로 연결되는 과정에서 복제본 노드의 데이터는 모두 삭제되기 때문에 기존 마스터가 네트워크 단절 동안 처리했던 모든 데이터는 유실된다. (ex. 레디스에 데이터를 입력했는데, 값을 찾을 수 없음)
'독서 > 개발자를 위한 레디스' 카테고리의 다른 글
| [개발자를 위한 레디스] 11장 보안 (0) | 2024.12.12 |
|---|---|
| [개발자를 위한 레디스] 10장 클러스터 (0) | 2024.12.07 |
| [개발자를 위한 레디스] 8장 복제 (0) | 2024.11.23 |
| [개발자를 위한 레디스] 7장 레디스 데이터 백업 방법 (0) | 2024.11.07 |
| [개발자를 위한 레디스] 6장 레디스를 메시지 브로커로 사용하기 (0) | 2024.10.29 |



