레디스 모니터링 구축하기
프로메테우스와 그라파나를 이용한 레디스 모니터링
레디스 모니터링 구조

- 익스포터(exporter): 시스템의 상태를 실시간으로 스크랩해서 메트릭을 수집하는 프로그램
- 프로메테우스: 메트릭 기반의 오픈 소스 모니터링 시스템
- 시계열 형태로 데이터 저장
- 지정한 타깃으로 직접 접근해 데이터를 pull 방식으로 수집
- 그라파나: 오픈 소스 메트릭 데이터 시각화 도구로, 데이터를 시각화해서 시스템의 분석과 모니터링을 용이하게 해주는 플랫폼
- 프로메테우스를 실행할 때 알람 규칙(alerting rule)을 설정할 수 있다.
- 수집한 메트릭을 그라파나로 볼 수 있다.
- 메트릭별 임계치를 지정할 수 있다.
- 특정 임계치에 도달했을 때 사용자에게 통지하기 위해 얼럿 매니저(alert manager) 프로그램을 사용한다.
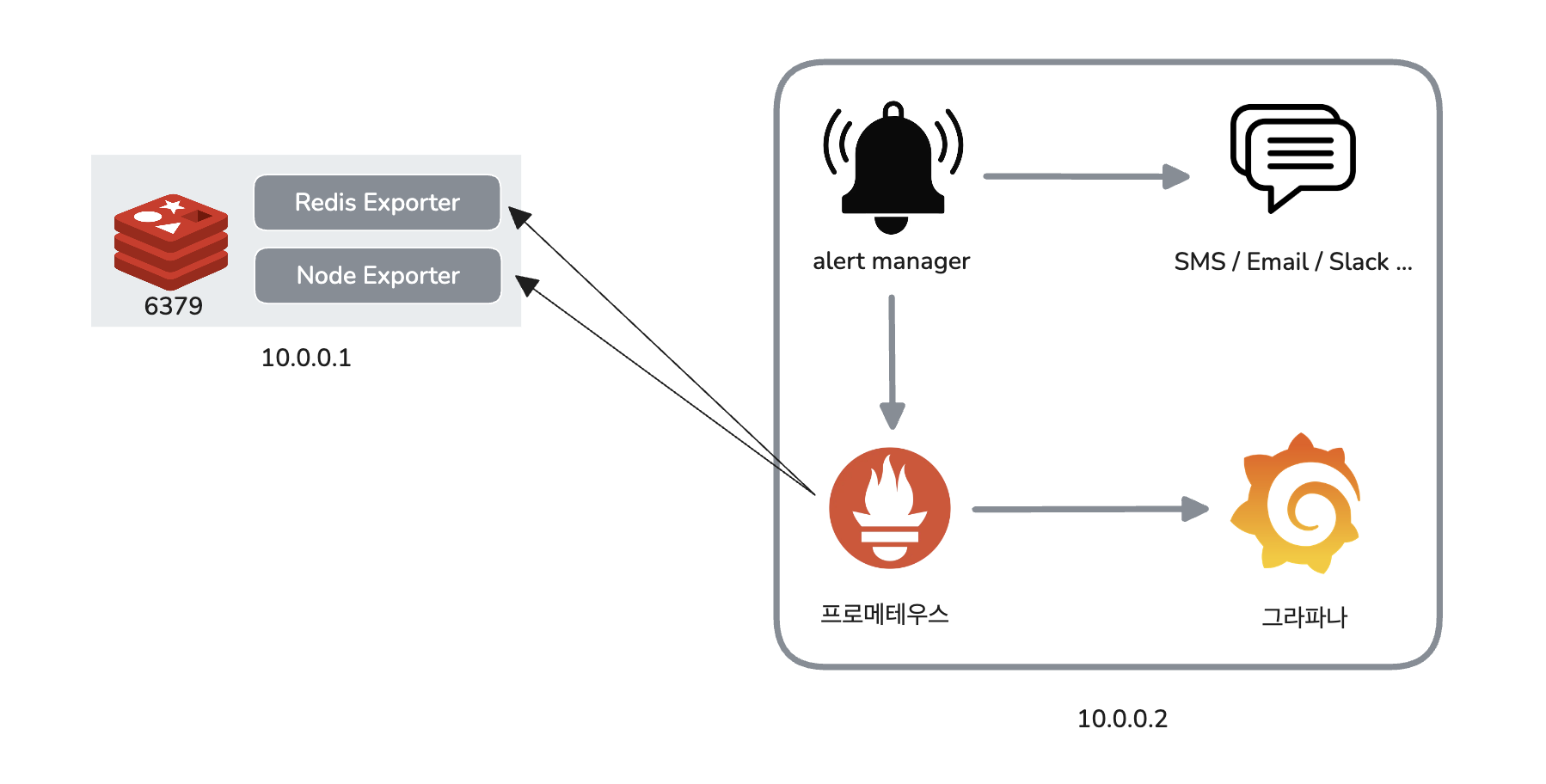
- 10.0.0.1 서버에는 레디스(6379), 레디스 익스포터(9121), 노드 익스포터(9100)가 띄워져 있다.
- 10.0.0.2 서버에는 프로메테우스와 그라파나가 띄워져 있다.
노드 익스포터 설치
$ wget https://github.com/prometheus/node_exporter/releases/download/v1.8.2/node_exporter-1.8.2.linux-amd64.tar.gz
$ tar -zxvf node_exporter-1.8.2.linux-amd64.tar.gz
$ rm node_exporter-1.8.2.linux-amd64.tar.gz
$ ln -s node_exporter-1.8.2.linux-amd64/ node_exporter노드 익스포터의 설치 파일 다운로드 및 압축 해제
$ cd node_exporter
$ nohup ./node_exporter > node_exporter.log &백그라운드로 노드 익스포터 실행
레디스 익스포터 설치
$ wget https://github.com/oliver006/redis_exporter/releases/download/v1.67.0/redis_exporter-v1.67.0.linux-amd64.tar.gz
$ tar -zxvf redis_exporter-v1.67.0.linux-amd64.tar.gz
$ rm redis_exporter-v1.67.0.linux-amd64.tar.gz
$ ln -s redis_exporter-v1.67.0.linux-amd64/ redis_exporter레디스 익스포터의 설치 파일 다운로드 및 압축 해제
$ cd redis_exporter
$ nohup ./redis_exporter > redis_exporter.log &백그라운드로 레디스 익스포터 실행
| 플래그 이름 | 환경변수 이름 | 설명 |
| redis.addr | REDIS_ADDR | 수집할 레디스의 주소, 기본은 redis://localhost:6379 |
| redis.user | REDIS_USER | ACL 기능을 이용해 보안 관리를 할 때 사용할 수 있는 레디스 유저의 이름 |
| redis.password | REDIS_PASSWORD | 레디스 인스턴스에 접근할 때 사용해야 하는 패스워드 |
| redis.password-file | REDIS_PASSWORD_FILE | 레디스 인스턴스에 접근할 때 사용해야 하는 패스워드 파일 |
| web.listen-address | REDIS_EXPORTER_WEB_LISTEN_ADDRESS | 수집 정보를 확인할 수 있는 웹주소, 기본은 0.0.0.0.:9121 |
설정 정보를 변경하고 싶다면, 레디스를 실행할 때 위와 같은 플래그를 추가하면 된다.
얼럿 매니저 설치
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-386.tar.gz
$ tar -zxvf alertmanager-0.27.0.linux-386.tar.gz
$ rm alertmanager-0.27.0.linux-386.tar.gz
$ ln -s alertmanager-0.27.0.linux-386/ altermanager얼럿 매니저 다운로드 및 압축 해제
$ cd alertmanager
$ vi alertmanager.ymlroute:
group_by: ['alertname', 'job']
group_wait: 0s
group_interval: 5s
repeat_interval: 1m
receiver: discord
receivers:
- name: discord
discord_configs:
- webhook_url: https://discord.com/api/webhooks/xxx/xxx특정 임계치에 도달했을 때 디스코드를 이용해 알람을 받도록 설정한다.
$ vi alter.rulesgroups:
- name: redis
rules:
-alert: RedisDown
expr: redis_up == 0
for: 0m
annotations:
summary: "Redis down (instance {{ $labels.instance}}"
- alert: RedisMissingMaster
expr: (count(redis_instance_info{role="master"}) or vector(0)) < 1
for: 0m
anntations:
summary: "Redis missing master (({{ $value }}))"
- alert: RedisReplicationBroken
expr: delta(redis_connected_slaves[1m]) < 0
for: 0m
annotations:
summary: "Redis replication broken (( {{ $value }}))"알람을 받을 정보에 대한 규칙을 생성한다.
$ nohup ./alertmanager --config.file=alertmanager.yml > alertmanager.log &백그라운드로 얼럿 매니저 실행 (실행 후 10.0.0.2:9093 접속)
프로메테우스 설치
$ wget https://github.com/prometheus/prometheus/releases/download/v3.0.1/prometheus-3.0.1.linux-386.tar.gz
$ tar -zxvf prometheus-3.0.1.linux-386.tar.gz
$ rm prometheus-3.0.1.linux-386.tar.gz
$ ln -s prometheus-3.0.1/ prometheus프로메테우스 다운로드 및 압축 해제
$ cd prometheus
$ vi prometheus.ymlglobal:
scrape_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- '10.0.0.2:9093'
rule_files:
- /home/centos/alertmanager/alert.rules
scrape_configs:
- job_name: Redis
statc_configs:
- labels:
instance: 'redis-server-1'
targets:
- '10.0.0.1:9121'
- job_name: Linux
static_configs:
- labels:
instance: 'redis-server-1'
targets:
- '10.0.0.1:9100'프로메테우스가 모니터링할 타깃은 prometheus.yml 파일 형태로 지정한다.
$ nohup ./promethues --config.file=prometheus.yml --storage.tsdb.path=./data --storage.tsdb.retention.time=30d --web.enable-lifecycle > prometheus.log &백그라운드로 프로메테우스 실행 (실행 후 10.0.0.2:9090 접속)
그라파나 설치
$ wget wget https://dl.grafana.com/enterprise/release/grafana-enterprise-11.4.0.linux-amd64.tar.gz
$ tar -zxvf grafana-enterprise-11.4.0.linux-amd64.tar.gz
$ rm grafana-enterprise-11.4.0.linux-amd64.tar.gz
$ ln -s grafana-enterprise-11.4.0/ grafana그라파나 다운로드 및 압축 해제
$ nohup bin/grafana-server start > grafana.log &백그라운드로 그라파나 실행 (실행 후 10.0.0.2:3000 접속, username/password -> admin/admin)
- 생성해둔 프로메테우스를 그라파나에서 데이터 소스로 추가함으로써 프로메테우스에 수집된 데이터를 그라파나에서 확인할 수 있다.
대시보드 생성
그라파나 공식 홈페이지(https://grafana.com/grafana/dashboards/)에서 다양한 대시보드를 제공한다. (추가 후 사용 가능)
레디스 플러그인을 이용한 그라파나 대시보드
중간 저장소(프로메테우스) 없이 그라파나에서 레디스의 데이터를 확인 및 관리하도록 한다. 그라파나에서 레디스 플러그인을 설치하면 RedisGrafana에서 제공하는 대시보드를 이용해 실시간으로 레디스의 상태를 확인할 수 있다.
- Redis 플러그인: 실시간 레디스의 정보를 확인할 수 있다.
- Redis Application 플러그인: 사용자가 원하는 대시보드를 손쉽게 추가할 수 있으며, 그라파나에서 바로 레디스에 커맨드를 수행할 수 있다.
레디스 버전 업그레이드
2가지 방식이 존재한다.
- 업그레이드할 버전의 레디스 인스턴스를 새로운 서버에 설치한 뒤, 기존 버전의 레디스의 데이터를 복제한다.
- 운영 중인 애플리케이션에서 레디스로의 접속 정보를 변경해야 한다.
- 접속 정보를 변경하는 것 외에는 다운타임이 존재하지 않는다.
- 실행 중인 레디스 인스턴스를 중지한 다음, 신규 버전의 레디스 소스 파일로 재실행한다.
- 애플리케이션에서 레디스의 접속 정보를 변경하지 않아도 된다.
- 싱글 구성의 레디스였다면 다운타임이 발생한다는 점을 고려해야 한다.
센티널 구성의 레디스 버전 업그레이드
다운타임 없이 전체 인스턴스를 업그레이드할 수 있다.
- 신규 버전의 레디스 바이너리 파일 다운로드
- 3대의 센티널 인스턴스 모두 중단
- 신규 버전 폴더에 기존의 sentinel.conf 복사
- 신규 바이너리 파일을 이용해 3대의 센티널 인스턴스 시작
- 복제본 인스턴스 중단
- 신규 버전 폴더에 기존의 redis.conf 복사
- 신규 바이너리 파일을 이용해 복제본 인스턴스 시작
- 센티널에서 수동 페일오버 수행
- 기존 마스터 인스턴스 중단
- 신규 버전 폴더에 기존의 redis.conf 복사
- 신규 바이너리 파일을 이용해 기존 마스터 인스턴스 시작
- 센티널에서 수동 페일오버 수행(페일백)
클러스터 구성의 레디스 버전 업그레이드
A,B,C 인스턴스가 마스터 / D,E,F 노드가 각각 A,B,C 노드의 복제본이라고 가정한다.
- D, E, F 노드 각각 버전 업그레이드
- D 노드에서 페일오버
- A 노드 업그레이드
- E 노드에서 페일오버
- B 노드 업그레이드
- F 노드에서 페일오버
- C 노드 업그레이드
레디스 운영 가이드
장애 또는 성능 저하를 유발할 수 있는 레디스의 설정 항목
maxmemory-policy
레디스가 메모리 한계에 도달했을 때 어떤 키를 제거할지를 결정하는 설정값
- 기본값: noeviction
- 데이터가 가득 차더라도 임의로 데이터를 삭제하지 않는다. (이후 데이터 저장 시 에러 반환)
- 권장 X
- allkeys-lru 설정 권장
stop-writes-on-bgsave-error
RDB 스냅숏이 정상적으로 저장되지 않았을 때 레디스로의 모든 쓰기 작업을 중지하는 역할
- 쓰기 작업이 중단되지 않기를 원한다면 비활성화해야 한다. (설정값 no)
- 기본 설정값: yes
자동 백업 옵션
백그라운드로 실행될 때는 COW(Copy-On-Write) 방식으로 작동하기 때문에 메모리 사용량이 최대 maxmemory의 2개까지 증가할 수 있다. 따라서 백업 작업은 의도한 시간에 의도한 레디스 인스턴스에서 실행될 수 있도록 설정하는 것이 좋다.
- save 옵션: 일정한 기간 동안 변경된 키 수의 개수가 조건에 맞을 때 자동으로 RDB 파일을 생성한다.
- 대규모 트래픽 환경에서 RDB 파일의 백업 빈도가 너무 높아질 수 있으므로, 기본 설정값(yes)을 사용하지 않는 것이 좋다.
- appendonly 옵션을 yes로 설정해서 AOF 형식의 백업을 수행하는 경우에도 주의해야 한다.
- 기본적으로 AOF 파일 크기가 기존 파일보다 100% 증가하면 자동 재작성이 발생한다.
- 해당 동작을 의도하지 않은 경우 auto-aof-rewrite-percentage 값을 0으로 변경해서 자동 재작성을 방지한다.
레디스 운영 및 성능 최적화
오래 걸리는 커맨드 사용
레디스에서는 O(N) 이상의 시간 복잡도를 갖는 커맨드를 사용하는 것을 지양해야 한다.
- KEYS, FLUSHALL과 같이 한 번에 여러 키에 접근하는 커맨드
- set, list, hash와 같이 하나의 자료 구조 안에 여러 개의 아이템을 가지고 있는 경우
키스페이스 커맨드
레디스에 저장된 키의 개수에 비례해 수행 시간이 증가한다.
- KEYS
- 시간복잡도 O(N), 키 개수에 비례해 출력 시간이 길어질 수 있으므로 SCAN 커맨드로 대체하는 것이 좋다.
- FLUSHALL / FLUSHDB
- 옵션 없이 사용하면 SYNC 방식으로 동작하며, 시간 복잡도는 O(N)이다.
- ASYNC 옵션을 함께 사용하면 데이터 삭제 작업이 백그라운드에서 수행되므로 다른 작업을 블락시키지 않는다.
자료 구조 공통 커맨드
- DEL
- 키를 삭제하는 커맨드
- UNLINK 커맨드를 사용해서 백그라운드 방식으로 키를 삭제할 수 있다.
- SORT / SORT_RO
- 키 내부의 아이템을 정렬해 반환한다.
- ALPHA 옵션을 사용해서 데이터를 사전 순으로 정렬해 조회할 수 있다.
- 시간복잡도 O(N + Mlog(M)) // N-리스트나 세트 내부의 아이템 수, M-반환되는 아이템 수
- SORT는 STORE 옵션으로 인해 쓰기가 가능한 커맨드로 분류되어 복제본에서 사용할 수 없다.
- SORT_RO는 STORE 옵션을 사용할 수 없고 읽기 전용으로 동작하여 복제본에서 사용할 수 있다.
set 관련 커맨드
- SDIFF / SDIFFSTORE
- 차집합을 수행한다.
- 시간복잡도 O(N) // N-연산에 수행되는 집합의 아이템의 총 개수
- SDIFF 커맨드는 차집합 연산의 결과를 반환한다.
- SDIFFSTORE 커맨드는 차집합 결과를 다른 집합에 저장한다.
- SUNION / SUNIONSTORE
- 합집합을 수행한다.
- 시간복잡도 O(N)
- SUNION 커맨드는 합집합 연산의 결과를 반환한다.
- SUINONSTORE 커맨드는 합집합 결과를 다른 집합에 저장한다.
- SINTER / SINTERSTORE / SINTERCARD
- 교집합을 수행한다.
- 시간복잡도 O(N*M) // N-가장 작은 집합의 카디널리티, M-연산을 수행하는 집합의 수
- SINTER 커맨드는 교집합 연산의 결과를 반환한다.
- SINTERSTORE 커맨드는 교집합 결과를 다른 집합에 저장한다.
- SINTERCARD는 교집합 연산으로 얻어진 집합의 카디널리티만 반환한다.
list 관련 커맨드
최악의 경우 list의 전체 데이터를 순회해야 한다.
- LINDEX
- 입력받은 인덱스 위치에 있는 아이템을 리턴한다.
- 시간복잡도 O(N) // N-인덱스에 있는 아이템에 도달하기 위해 지나쳐야 하는 아이템의 개수
- LINSERT
- 피봇(pivot) 값을 필수 인자로 입력받는데, 해당 피봇 값의 이전 또는 이후에 신규 아이템을 입력하도록 동작한다.
- 시간복잡도 O(N) // N-피봇 값까지 도달하기 위해 지나쳐야 하는 아이템의 개수
- LSET
- 특정 인덱스의 아이템을 신규 입력한 문자열로 변경한다.
- 시간복잡도 O(N) // N-list의 길이
- LPOS
- 해당 아이템의 인덱스를 리턴한다.
- 시간복잡도 O(N) // N-평균적인 경우 list의 길이
hash 관련 커맨드
키-값 형태를 가지고 있기 때문에 다양한 객체를 저장하기에 적절하다.
- HGETALL
- hash에 저장된 모든 아이템의 키와 값을 리턴한다.
- 시간복잡도 O(N)
- HKEYS
- hash에 저장된 모든 아이템의 키를 리턴한다.
- 시간복잡도 O(N)
- HVALS
- hash에 저장된 모든 아이템의 값을 리턴한다.
- 시간복잡도 O(N)
sorted set 관련 커맨드
데이터가 입력될 때 자동으로 정렬되므로 기본적으로 O(log(N))의 시간 복잡도를 갖는다.
- ZDIFF / ZDIFFSTORE
- 차집합을 수행한다.
- 시간복잡도 O(L + (N-K) log(N)) // L-모든 집합의 총 아이템 수, N-첫 번째 세트의 크기, K-결과 세트의 크기
- ZUNION / ZUNIONSTORE
- 합집합을 수행한다.
- 시간복잡도 O(N) + O(M * log(M)) // N-모든 집합의 총 아이템 수, M-결과 집합의 아이템 수
- ZINTER / ZINTERSTORE / ZINTERCARD
- 교집합을 수행한다.
- 시간복잡도 O(N*K) + O(M * log(M)) // N-가장 작은 집합의 카디널리티, K-연산을 수행하는 집합의 수, M-결과 집합의 카디널리티
레디스에서의 트랜잭션 사용과 주의 사항
레디스는 싱글 스레드로 동작하기 때문에 트랜잭션을 사용할 때 주의해야 한다.
MULTI / EXEC
- MULTI는 트랜잭션을 시작하는 커맨드다.
- EXEC 커맨드를 사용하면 입력했던 커맨드를 원자적으로 실행하고, 트랜잭션이 성공하면 결과를 반환한다.
> MULTI
OK
(TX)> INCRBY account_balance 100
QUEUED
(TX)> RPUSH tranaction_log "입금 100"
QUEUED
(TX)> EXEC
1) (integer) 100
2) (integer) 1잔고를 100 증가시키고, 거래 로그에 입금 내역을 추가하는 예제 명령어
루아 스크립트
- 가볍고 빠르며 임베디드가 가능한 스크립트 언어
- 원자적으로 실행되므로 여러 명령을 한 번에 실행할 수 있다.
- 중간에 다른 클라이언트 요청을 수용하지 않아 데이터 일관성을 유지할 수 있다.
- 일부 명령어가 실패하더라도 다음 명령어로 진행되며 롤백이 발생하지 않는다.
- SCRIPT LOAD 커맨드는 루아 스크립트를 레디스에 로드하는 커맨드이다.
- EVALSHA를 사용하면 스크립트를 다시 전송하지 않고도 스크립트를 반복해 실행할 수 있다. (네트워크 대역폭 절약)
트랜잭션과 루아 스크립트 사용할 때의 주의점
다른 클라이언트의 커맨드는 모두 대기하게 되므로, 트랜잭션의 길이가 길어지지 않도록 주의가 필요하다.
- has-get / has-del 패턴
- 레디스에서 데이터 조회 또는 삭제 시 EXISTS 커맨드를 사용해 데이터 존재 여부를 확인한 뒤 처리한다.
- 이러한 패턴은 네트워크 부하를 늘리며, 불필요한 작업을 수행해 애플리케이션의 성능을 저하시킬 수 있다.
- 불필요한 패턴을 없앰으로써 2배의 성능 개선을 이뤄낼 수 있다.
클라이언트 출력 버퍼 사이즈
- 클라이언트 출력 버퍼는 클라이언트가 서버로부터 응답을 받을 때 이를 일시적으로 저장한다.
- 복제를 사용하는 경우 출력 버퍼의 크기를 늘리는 것이 필수적이다. (큰 데이터를 복제할 때 버퍼 크기 모자랄 수 있음)
- redis.conf 파일에서 client-output-buffer-limit 설정을 구성할 수 있다.
- client-output-buffer-limit normal 0 0 0
- 출력 버퍼 제한 비활성화
- client-output-buffer-limit replica 256mb 64mb 60
- 복제본에 대한 출력 버퍼
- 하드 제한 256MB
- 소프트 제한 64MB
- 소프트 제한을 초과한 경우 60초 동안 소프트 제한을 계속 초과하면 클라이언트 연결 종료
- client-output-buffer-limit pubsub 32mb 8mb 60
- pub/sub 클라이언트에 대한 출력 버퍼
- 하드 제한 32MB
- 소프트 제한 8MB
- 소프트 제한을 초과한 경우 60초 동안 소프트 제한을 계속 초과하면 클라이언트 연결 종료
- client-output-buffer-limit normal 0 0 0
레디스 키스페이스 알림 기능을 사용한 키 만료 모니터링
키스페이스 알림 기능은 레디스 내부 키에 대한 변경 사항을 모니터링하며 내부의 pub/sub 채널을 이용해 변경 사항에 대한 메시지를 구독할 수 있는 기능이다.
- K(키스페이스 이벤트): 이벤트가 발생한 데이터베이스에 대해 keyspace@<db> 접두사와 함께 발행
- E(키 이벤트): 이벤트가 발생한 데이터베이스에 대해 keyevent@<db> 접두사와 함께 발행
- g(일반적인 명령 이벤트): DEL, EXPIRE, RENAME 등과 같은 명령어와 관련된 이벤트
- $: 문자열 명령어와 관련된 이벤트
- l: 리스트 명령어와 관련된 이벤트
- s: 집합 명령어와 관련된 이벤트
- h: hash 명령어와 관련된 이벤트
- z: 정렬 집합 명령어와 관련된 이벤트
- t: stream 명령어와 관련된 이벤트
- x: 만료된 키 이벤트
- e: 삭제된 키 이벤트
- m: 누락된 키 이벤트
- n: 새로운 키 이벤트
- A: 'm', 'n' 이벤트를 제외한 모든 이벤트를 포함
특정 프리픽스를 가진 키 삭제하기
pattern = 'prefix:*'
count = 100
cursor, keys = 0, []
# SCAN 명령을 사용해 특정 프리픽스를 가진 키 검색
while True:
cursor, partial_keys = r.scan(cursor, match=pattern)
keys.extend(partial_keys)
if cursor == 0:
break
# 검색된 키 삭제
for key in keys:
r.delete(key)pattern 변수에 prefix:*와 같은 패턴을 설정하며, 'prefix:'로 시작하는 모든 키를 검색하라는 의미의 코드.
- SCAN 명령은 한 번에 모든 키를 반환하지 않고, 커서 값을 업데이트하면서 페이지 단위로 키를 반환한다.
# 삭제할 키의 패턴 및 스캔 파라미터 설정
pattern = 'prefix:*'
count = 100
cursor = "0"
# 루아 스크립트 정의
lua_script = """
local cursor = ARGV[1]
local pattern - ARGV[2]
local count = ARGV[3]
local keys = redis.call("SCAN", cursor, "MATCH", pattern, "COUNT", count)
local cursor = keys[1]
local keyList = keys[2]
for _, key in ipairs(keyList) do
redis.call("DEL", key)
end
return {cursor, #keyList}
"""
total_deleted_count = 0
# 반복적으로 루아 스크립트를 호출해 키를 조회하고 삭제
while True:
result = r.eval(lua_script, 0, cursor, pattern, count)
cursor, deleted_count = result[0], result[1]
total_deleted_count += deleted_count
if cursor == "0":
break루아 스크립트를 이용한다면 네트워크 I/O를 줄이면서 같은 작업을 효율적으로 수행할 수 있다.
- 매번 DEL 명령을 호출하는 과정이 생략됐다.
- 스크립트가 실행되는 동안 다른 클라이언트의 커맨드는 차단될 수 있으므로, 운영 환경에서는 적절한 배치 크기로 count 매개변수를 조절해 차단 시간을 최소화해야 한다.
레디스 모니터링
슬로우 로그
: 실행 속도가 느린 커맨드를 기록하는 로그
> SLOWLOG GET
1) 1) (integer) 1923
2) (integer) 1696344048
3) (integer) 35233
4) 1) "SCAN"
2) "10179327"
3) "COUNT"
4) "50000"SLOWLOG GET 커맨드를 이용해서 슬로우 로그를 확인할 수 있다.
- 실행 시간(timestamp): 명령이 실행된 시간 정보
- 실행 시간(ms): 명령이 실행되는 데 소요된 시간
- 명령: 느리게 수행됐던 커맨드
- 인자: 느린 명령에 대한 인자 정보
그래프 지표
- 안정적인 레디스 운영을 위해 각 메트릭 지표를 적절하게 모니터링해야 한다.
- 중요한 컴퓨팅 자원을 얼마나 쓰고 있는지 확인하는 것이 중요하다.
CPU
- 백업 파일 저장 및 UNLINK와 같은 백그라운드 작업 시에는 다른 CPU를 활용할 수 있다. (모니터링 중요)
- 작업의 시간 복잡도를 고려해서 불필요한 작업을 최소화하는 것이 좋다.
- 읽기 작업이 부하를 일으키는 경우 읽기 작업을 복제본을 참조하도록 변경한다.
- 백업 작업이 부하를 일으키는 경우 가능한 백업을 복제본에서 수행하고, 복제 환경에서는 전체 재동기화가 발생하지 않도록 한다.
메모리
- used_memory: 레디스가 현재 할당한 메모리
- used_memory_rss: 운영체제가 레디스 프로세스에 할당한 실제 물리적인 메모리 양 반영
- BytesUsedForCache(현재 메모리 사용량)와 DatabaseMemoryUsagePercentage(maxmemory의 백분율 계산)와 같은 메트릭을 활용할 수 있다.
- 메모리 단편화를 관리하기 위해 active defragmentation 기능을 활성화한다. (문제 없으면 활성화 필요 없음)
- CONFIG SET activedefrag yes
네트워크
- 네트워크 모니터링을 통해 네트워크 지표가 어느 정도로 상승하는지 확인하는 것이 중요하다.
- 병목 현상이 발생하고 있는지 확인하는 것이 좋다.
- 네트워크 증가 원인 및 해결
- 읽기: 읽기 작업이 복제본을 주로 활용하고 있는지 확인한다. 아니면 추가 복제본을 구성해 해결할 수 있다.
- 쓰기: 서버의 사양을 업그레이드한다. 또는 레디스를 클러스터 모드로 변경해 해결할 수 있다.
커넥션
- 레디스의 활성 연결 수와 신규 연결 수를 확인해 일반적인 수준과 다른 변화가 있는지 주시해야 한다.
- tcp-keepalive 설정을 활용하면 유휴 연결로 인한 문제를 에방할 수 있다.
- 매 300초마다 연결의 유효성을 확인하고 문제가 있는 경우 연결을 종료하는 과정을 반복한다.
- 기존 연결을 재사용하기 위해 커넥션 풀링을 사용하는 것이 좋다.
- TLS를 사용해 통신하는 경우 새로운 연결의 양을 제어하는 것이 중요하다.
복제
- 복제 지연이 발생하는지 확인하는 것이 중요하다.
- 복제 지연의 급증은 마스터 노드의 속도를 복제본이 따라가지 못하는 것을 의미한다.
- 복제 지연이 발생한다면 원인을 파악하고 조치하기 위해 다른 메트릭을 확인하는 것이 좋다.
- ex. 네트워크 대역폭의 고갈, 복제 출력 버퍼 크기 문제 등
'독서 > 개발자를 위한 레디스' 카테고리의 다른 글
| [개발자를 위한 레디스] 11장 보안 (0) | 2024.12.12 |
|---|---|
| [개발자를 위한 레디스] 10장 클러스터 (0) | 2024.12.07 |
| [개발자를 위한 레디스] 9장 센티널 (1) | 2024.12.02 |
| [개발자를 위한 레디스] 8장 복제 (0) | 2024.11.23 |
| [개발자를 위한 레디스] 7장 레디스 데이터 백업 방법 (0) | 2024.11.07 |



